API Integrations That Don't Break
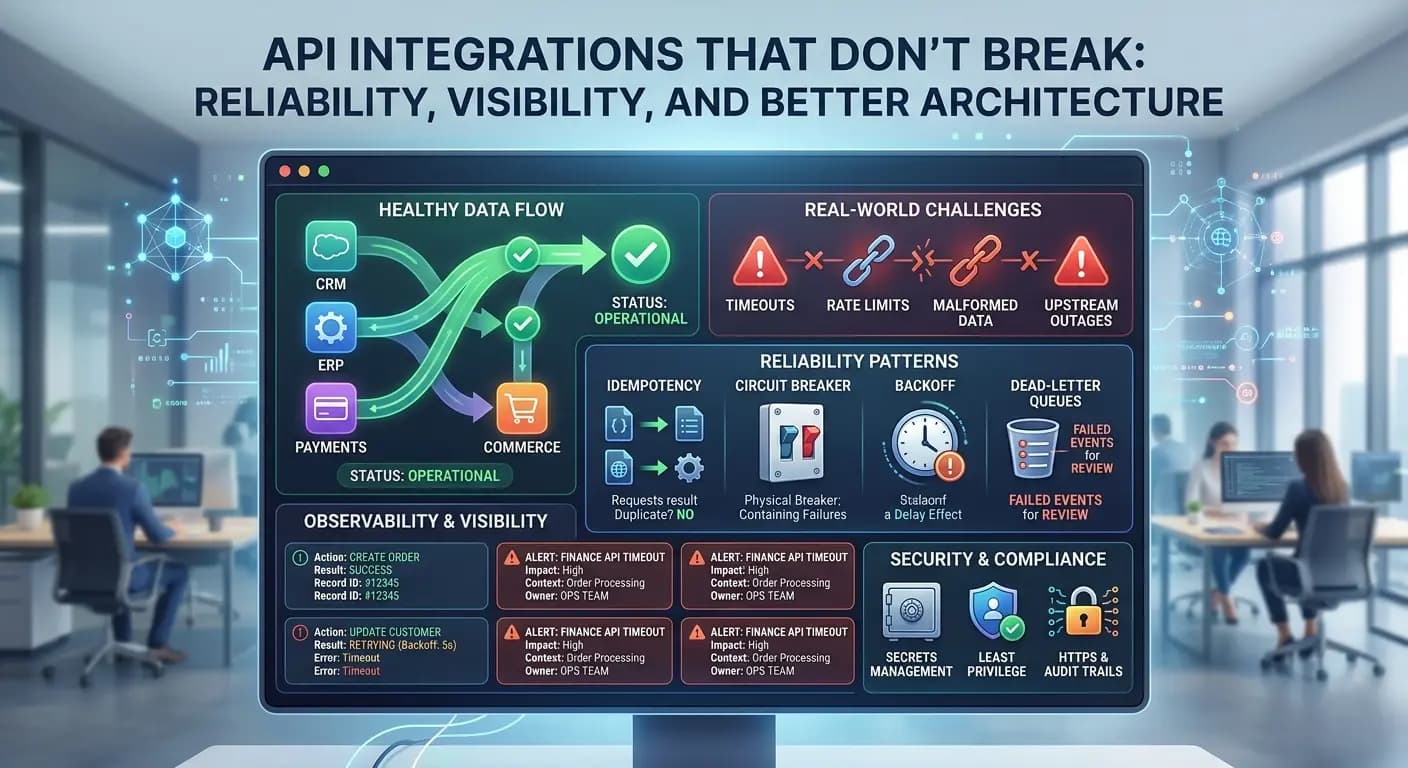
Operational integration is not just data moving between systems. It is reliability plus visibility: the integration layer should keep working under real conditions and show operators what moved, what failed and what needs attention. That is the same approach behind Fintiq's Systems Integration work, where validation, observability, logging and recovery paths matter as much as the connection itself. When a workflow needs more structured delivery, Automation Engineering helps turn the integration into something operations can actually support.
Why integrations fail in real life
Most integrations do not fail because the API can never connect. They fail because production conditions are messier than the demo. A downstream service may time out. A vendor may rate-limit requests during a scheduled batch job. Source data may arrive malformed, with missing fields, bad dates or unexpected values. Upstream outages can break event-driven integration flows even when your own systems are healthy.
Data mismatches add another layer of risk when CRM, finance and operations tools interpret statuses, IDs or customer records differently. The result is usually not a dramatic crash. It is integration drift, reconciliation effort, delayed handoffs and growing mistrust in the data.
That is why validation and recovery paths matter as much as the connection itself. The exception path is part of the design, not an afterthought.
The reliability patterns that matter most
Reliable API orchestration is usually built from a few practical patterns that reduce duplicate side effects, contain failure and make data synchronisation easier to support in real operations.
Idempotency and safe retries
Retries are necessary, but blind retries can create a bigger mess than the original failure. If a create request succeeds on the target side and the response is lost in transit, retrying without control can produce duplicate invoices, orders or customer records.
Idempotency avoids that by making the same logical request safe to replay. A stable request or operation key lets the receiving system recognize a duplicate attempt as the same action rather than a new one. For business-critical integrations, that is one of the most useful API integration best practices because it preserves recovery without multiplying cleanup work.
Backoff, circuit breakers and timeouts
Not every failure deserves an immediate second attempt. When a service is already slow or unstable, aggressive retries can worsen the problem. A retry and backoff pattern spaces attempts out over time so the dependency has room to recover.
Sensible timeouts matter too because an integration should not hang forever waiting for one step to return. Circuit-breaker style controls can also help by pausing new calls when a downstream system is clearly unhealthy. The point is containment. A local dependency issue should not cascade across the whole workflow.
Validation, dead-letter queues or failed-event lists
Validation should happen before a request leaves the integration layer. Required fields, accepted values, schema expectations and basic business rules should be checked before data is pushed downstream.
If a record still fails, it needs somewhere deliberate to go: a dead-letter queue, failed-event list or operational dashboard. Failed transactions should be visible and recoverable, not buried in a generic error log. If you want the larger operating model behind that approach, the SME systems integration article covers the surrounding integration discipline in more detail.
Clear ownership and escalation
Technical controls are not enough if nobody owns the workflow when it breaks. Every important integration needs an owner, a basic runbook and an escalation path.
If retries are exhausted, someone should know. If reconciliation issues recur, someone should investigate whether the source data, mapping logic or process design needs to change. Ownership is part of reliability because unclear responsibility turns small failures into long-running operational drag.
Observability, logging and alerting as a product feature
Observability should be treated as part of the product, not as an optional extra added after go-live. Operators need to see what ran, which record was processed, what failed, whether it retried and what needs action next.
That is why API integration logging and monitoring should be designed for use, not just for storage. OWASP's Logging Cheat Sheet notes that process monitoring, audit and transaction logs are collected for distinct purposes, and that logged event data needs to be available for review with appropriate monitoring, alerting and reporting processes in place. It also recommends that logs capture useful context such as action, object and result status, which is exactly the kind of detail operators need when working through failed runs.
Alerting also needs context. "Workflow failed" is rarely enough. A useful alert should point to the affected integration, the failed step, the relevant record and the likely next action. Good integration runbooks and dashboards shorten diagnosis time, reduce manual guesswork and make support more practical for scheduled batch jobs and event-driven flows alike.
In other words, visibility is not decoration. It is what turns an integration from a fragile technical link into a supportable operational system over time.
Security and compliance basics for integration
Security for integrations should be pragmatic. Start with least privilege. Grant each workflow only the access it actually needs, and make sure token scope matches the business process rather than the broadest possible permission set.
Secrets management matters just as much. OWASP's Secrets Management Cheat Sheet says there is a growing need for organizations to centralize the storage, provisioning, auditing, rotation and management of secrets. It also recommends standardizing and centralizing secrets handling, using fine-grained access controls based on least privilege, and reducing manual handling because manual maintenance increases leakage risk and human error.
For integrations, that means API keys, tokens and credentials should sit in a proper secrets management process rather than in inboxes, scripts or shared notes. OWASP's REST Security Cheat Sheet also reminds teams to keep REST services on HTTPS so credentials and tokens are protected in transit and transmitted data integrity is preserved. Audit logs then help trace what was created, updated, retried or overridden during operations.
Together, least privilege, secrets management and audit logs form a practical minimum for secure, supportable integrations.
When to get help
A point comes when the issue is no longer a small fix. If your team keeps dealing with reconciliation problems, unclear ownership, weak monitoring or integrations that fail without a clear explanation, the design likely needs attention.
That is where an integration partner can help: tightening the integration layer, improving observability and making the workflow supportable in real operations. Review the connected pages below, then book a consultation if you want to strengthen API integrations before they create more hidden failures, manual cleanup and avoidable operational drag.